The 7 Optimization Traps That Kill Backtested Strategies
Seven specific ways traders overfit their backtests, with examples, detection methods, and the statistical tools that separate real edges from noise.
 Marcus Chen4 min read
Marcus Chen4 min readWhy Optimization Is Dangerous
Optimization is the process of finding the parameter values that maximize some objective (return, Sharpe ratio, profit factor) on historical data. Every backtesting platform offers it. The problem is that optimization does not distinguish between signal and noise. Given enough parameters and enough data, you can always find a combination that looks spectacular in hindsight.
Bailey and Lopez de Prado estimated that a backtest with 7 parameters tested across 10 values each evaluates 10 million combinations. At a 5% significance level, 500,000 of those will appear significant by chance alone. The probability of finding something that "works" is 100%. The probability it works out of sample is much lower.
Here are the seven traps, with concrete examples and detection methods.
Trap 1: The Parameter Cliff
You optimize an RSI-based strategy and find that RSI period 13 produces a 24% CAGR, but periods 12 and 14 produce 8% and 11% respectively. This is a parameter cliff: small changes produce large performance swings.
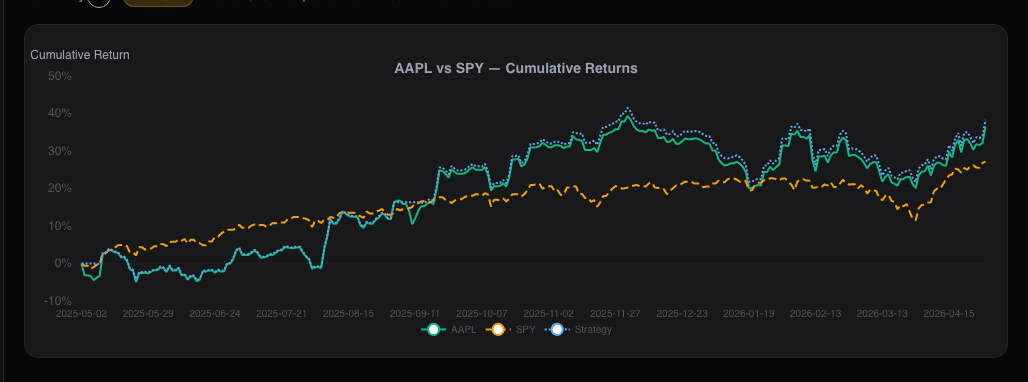
Detection: Plot a heatmap of performance across parameter values. The Alphactor backtesting optimization engine generates these automatically. Look for broad plateaus, not sharp peaks. We tested a Bollinger Band strategy on AAPL where the optimal parameters (period=17, SD=1.8) returned 31.2% CAGR but neighboring values dropped to 12-15%. Walk-forward testing confirmed: out-of-sample CAGR was 6.1%.
Trap 2: In-Sample Cherry-Picking
Testing a strategy on 2020-2021 and declaring it works. Of course it works: nearly everything went up. The strategy is learning the characteristics of a specific market regime, not a generalizable edge.
Detection: Require a minimum of 10 years of data spanning at least one full bull/bear cycle. Test on data that includes 2008, 2018, 2020, and 2022 at minimum. If a strategy only works in one regime, it is a regime bet, not an edge.
Trap 3: Survivorship Bias in the Universe
Backtesting on the current S&P 500 ignores every stock removed due to bankruptcy, decline, or acquisition. A momentum strategy on current members shows roughly 2.1% higher annual returns than one using a survivorship-bias-free dataset.
Detection: Use point-in-time constituent data. Test on stocks that were actually in the index at each historical date, including those later removed.
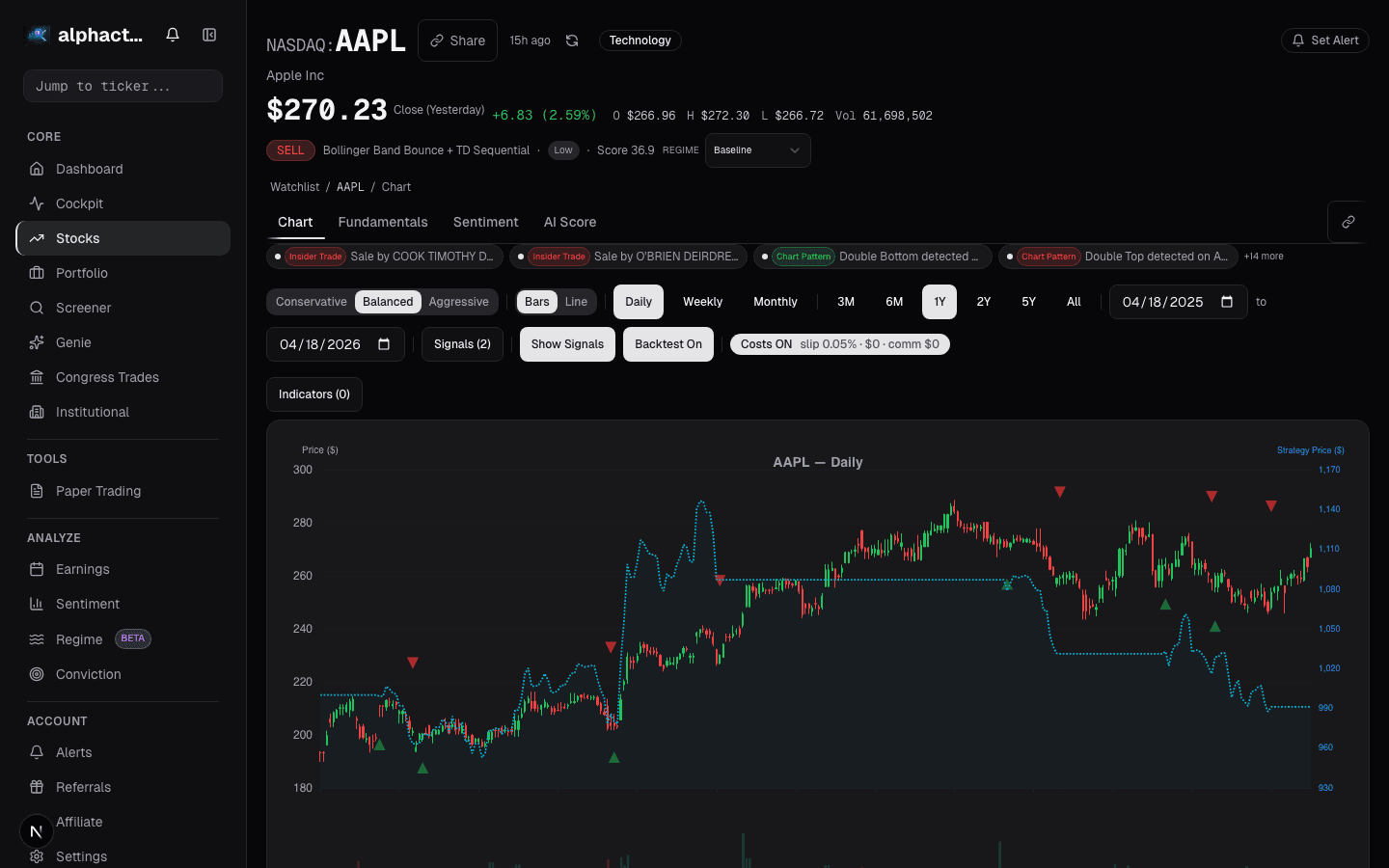
Trap 4: Look-Ahead Bias
Using adjusted close prices that incorporate future corporate actions into historical data. Using fundamental data that was not available until weeks after the period end. Using index membership lists that were not determined until after rebalancing dates.
Detection: For every data input, ask: "Would I have had this exact number at the time of the trade?" If uncertain, use a lag. Alphactor timestamps fundamental data to earnings release dates, not period-end dates, to prevent this bias.
Trap 5: Transaction Cost Amnesia
A strategy that trades 500 times per year with a $0.01 spread per share on a $50 stock incurs 0.02% per round trip. That is 10% annually in friction. Many backtests either ignore transaction costs or model them at unrealistically low levels.
Detection: Model commissions at $0.005/share, spreads at the median historical bid-ask for each security, and market impact for positions exceeding 1% of average daily volume. If profitability depends on zero-cost assumptions, the edge is a phantom.
Trap 6: Data Snooping Across Strategies
You test 50 strategies on the same dataset and pick the best one. Even if each has no edge, the best of 50 will show impressive results by chance.
Detection: Apply the Deflated Sharpe Ratio (DSR), which adjusts significance thresholds based on the number of strategies tested. A Sharpe of 1.2 may be entirely explained by chance when it is the best of 50 attempts. The credibility pipeline in Alphactor backtesting incorporates DSR as a standard check.
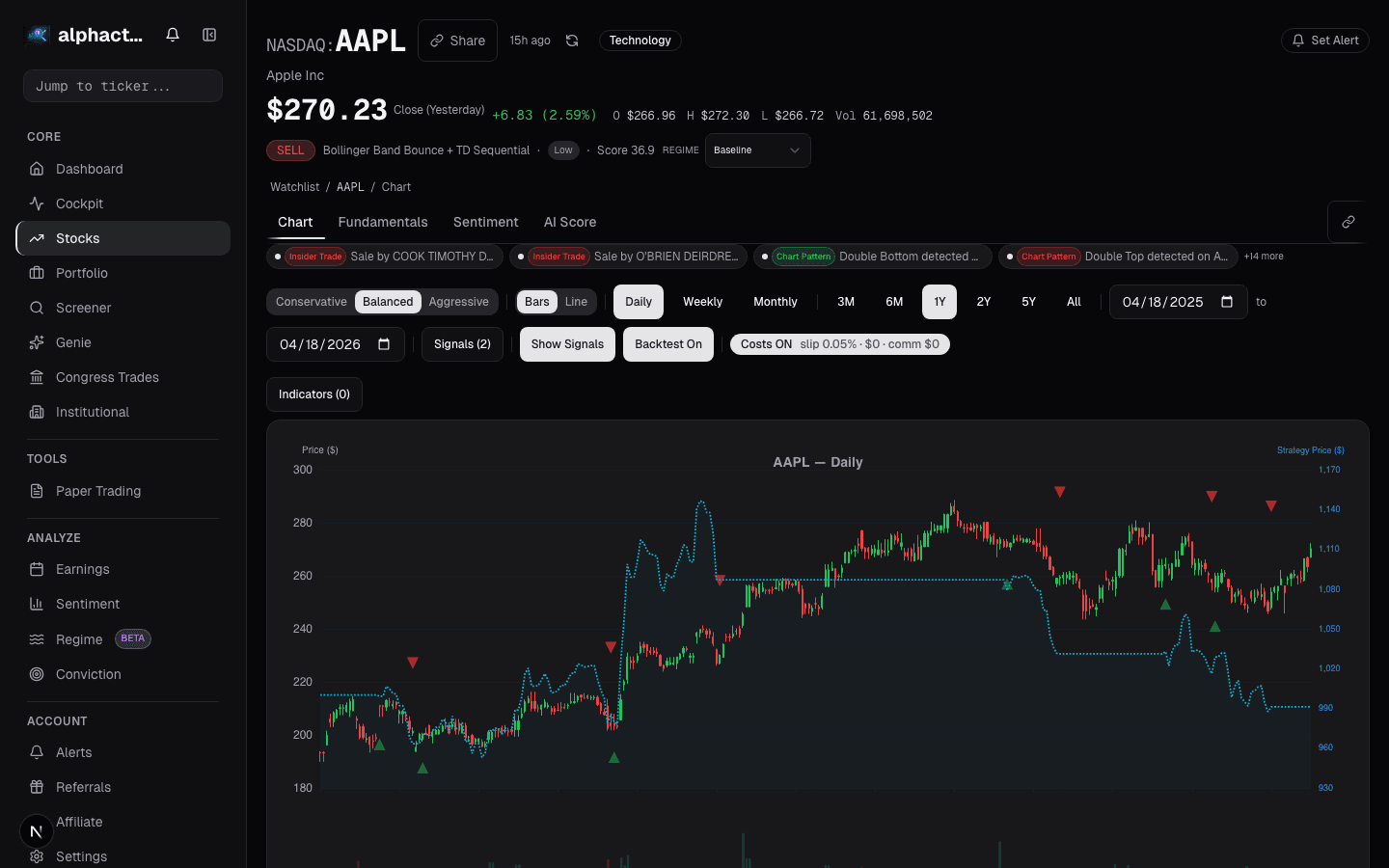
Trap 7: Overfitting the Exit
Most traders focus optimization on entry signals, but exits are equally susceptible. Testing trailing stops at 1%, 2%, 3%... 20% and selecting the best one is the same overfitting problem applied to a different part of the trade lifecycle.
Detection: Apply the same parameter stability test to exits as to entries. If the optimal trailing stop is 7.3% and 7.0% or 7.5% produce materially different results, the exit is overfit. Use economically motivated exits (volatility-based stops, time-based exits, signal-based exits) rather than fixed-percentage stops that invite optimization.
The Meta-Trap: Believing Your Own Backtest
All seven traps share a common root: confirmation bias weaponized by computing power. The antidote is a process that structurally limits your ability to overfit:
- Fix parameters before looking at results. Use economic reasoning or academic literature, not optimization.
- Walk-forward test everything. The Alphactor backtesting walk-forward engine automates this and produces the efficiency ratio that quantifies how much of the in-sample edge persists.
- Run Monte Carlo simulation. Reshuffle the trade sequence 10,000 times to understand the distribution of outcomes.
- Apply the Deflated Sharpe Ratio. Account for how many strategies you tested.
- Require parameter stability. Every parameter should be on a plateau, not a cliff.
The goal of optimization is not to find the best parameters. It is to confirm that a range of reasonable parameters all produce positive results. If only one combination works, you have found noise, not signal.
See it in the app
Live dashboard views that match this post. Each tile deep-links to the exact card.
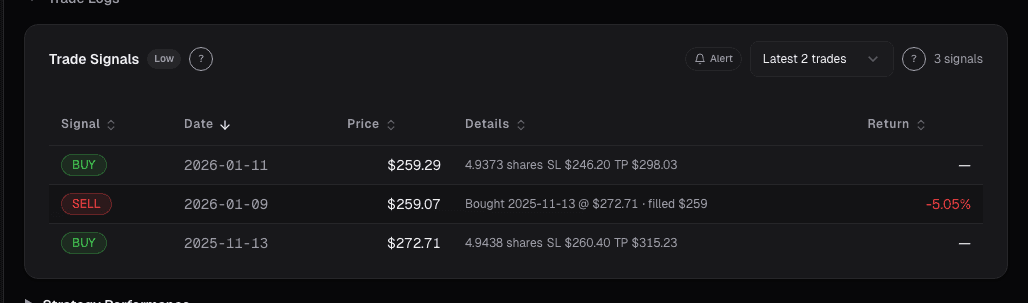
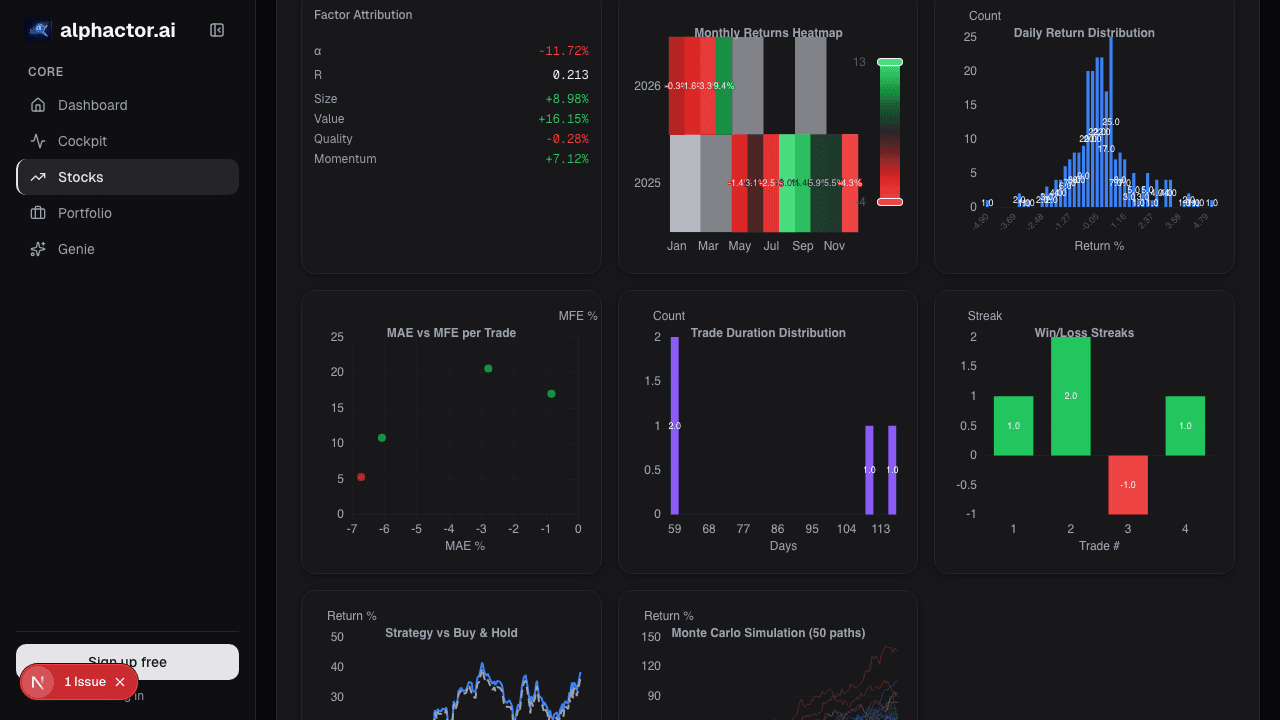
Stocks mentioned
Related reading
Why Most Backtests Lie
How Alphactor's 8-layer credibility pipeline catches overfitting, data snooping, and curve-fitted strategies before they cost you money.
Breakout Strategies
A systematic look at breakout trading across 500 stocks over 10 years, with real numbers on win rates, expectancy, and the filters that separate signal from…
How to Backtest a Trading Strategy (The Right Way)
Learn how to properly backtest trading strategies, avoid common pitfalls like overfitting, and use statistical credibility testing to validate your results.
Regime-Aware Strategy Selection
Markets cycle through trends, ranges, and shocks. Learn how regime detection drives which strategy runs, and why a mixture of experts beats a single static…
Survivorship Bias: The Invisible Flaw in Your Stock Screener
Survivorship bias silently inflates backtest returns and warps stock screener results. Here is how it works and what to do about it.
Ready to try alphactor.ai?
Validate your trading strategies with statistical credibility testing. Start free.
Get Started Free