Walk-Forward Testing: The Only Backtest That Matters
Why walk-forward testing is the gold standard for strategy validation, how it works mechanically, and what the efficiency ratio tells you about real versus…
 Marcus Chen4 min read
Marcus Chen4 min readThe Problem With Standard Backtests
A standard backtest optimizes parameters on a historical dataset and reports performance on that same dataset. This is like studying the answer key before taking a test. Of course you score well. The question is whether you actually learned the material.
Even a train/test split (optimize on the first 70% of data, validate on the last 30%) has a fatal flaw: you run the test once, see the results, adjust your strategy, and re-run. After a few iterations, the "out-of-sample" data is effectively in-sample because your decisions were influenced by it. This is information leakage, and it is nearly impossible to avoid in a single-split framework.
Walk-forward testing solves this by using multiple non-overlapping out-of-sample windows, each of which is tested exactly once. It is the closest thing to simulating real-time deployment without actually deploying.
How Walk-Forward Testing Works
The mechanics are straightforward:
- Define an in-sample window (e.g., 36 months) for parameter optimization
- Define an out-of-sample window (e.g., 12 months) for validation
- Optimize parameters on the in-sample window
- Apply those parameters to the out-of-sample window and record performance
- Roll forward by the out-of-sample length and repeat
For a 20-year dataset with 36-month in-sample and 12-month out-of-sample windows:
- Window 1: Optimize on months 1-36, test on months 37-48
- Window 2: Optimize on months 13-48, test on months 49-60
- Window 3: Optimize on months 25-60, test on months 61-72
- Continue until data is exhausted
Each out-of-sample window uses parameters that were determined before that window began. The strategy never sees the data it is tested on during optimization. This eliminates the information leakage that plagues single-split and full-sample backtests.
The Efficiency Ratio
The walk-forward efficiency ratio is the core output metric:
Efficiency Ratio = Out-of-Sample Performance / In-Sample Performance
If a strategy returns 15% annually in sample and 11% out of sample, the efficiency ratio is 0.73. This tells you that 73% of the apparent in-sample edge persisted when tested on unseen data.
Benchmarks from our testing across hundreds of strategies on Alphactor backtesting:
- Above 0.80: Strong evidence of a real edge. The strategy is robust.
- 0.50 to 0.80: Moderate evidence. The edge exists but is weaker than in-sample results suggest. Deploy with reduced position sizing.
- 0.30 to 0.50: Weak evidence. Possible edge, but likely amplified by in-sample fitting. Requires additional validation.
- Below 0.30: No credible evidence. The in-sample performance was almost entirely driven by curve fitting. Do not deploy.
We analyzed 312 strategies submitted by Alphactor users. Only 42% had efficiency ratios above 0.50. The other 58% were substantially or entirely explained by in-sample fitting. Without walk-forward testing, those traders would have deployed capital on strategies with no credible edge.
Choosing Window Sizes
Rules of thumb from our research:
- In-sample window: 3-5x the average holding period, minimum 36 months
- Out-of-sample window: 6-12 months for monthly strategies, 3-6 months for weekly
- Step size: Typically equal to the out-of-sample window length
We tested a trend-following strategy with varying configurations. The 48-month/12-month setup produced an efficiency ratio of 0.74, while 36-month/12-month yielded 0.71. The modest difference across configurations is itself a positive signal: the strategy is not sensitive to the validation framework.
Common Mistakes
Re-running after seeing results. If you tweak the strategy and re-run walk-forward testing, you are snooping on the out-of-sample data. The first result is the valid one.
Optimizing the walk-forward parameters. Choosing window sizes that produce the highest efficiency ratio is a meta-optimization problem. Fix them before running the test.
Ignoring the distribution. An efficiency ratio of 0.70 that comes from 10 excellent periods and 6 terrible ones indicates bimodal performance. Examine consistency across individual windows, not just the aggregate.
Walk-Forward Combined With Monte Carlo
Walk-forward testing validates that the edge persists out of sample. Monte Carlo simulation validates that the trade sequence does not flatter the results. Together, they provide two independent forms of evidence.
After walk-forward testing, reshuffle the out-of-sample trade sequence 10,000 times. For a strategy with an efficiency ratio of 0.75 and an out-of-sample CAGR of 12%, Monte Carlo analysis produced a 5th percentile CAGR of 6.2% and a 95th percentile max drawdown of -28.4%. Use the 5th percentile return for capital allocation and the 95th percentile drawdown for risk management. The point estimate from the backtest is the median case, not the expected case.
Alphactor runs both walk-forward and Monte Carlo analysis as part of its credibility pipeline. Strategies that pass both with an efficiency ratio above 0.50 and positive 5th percentile returns earn a credibility rating that reflects genuine statistical evidence. See how your own strategies score on the leaderboard.
The Only Backtest That Matters
A strategy that returns 25% annually in a standard backtest but has a walk-forward efficiency ratio of 0.20 is worthless. A strategy that returns 10% with an efficiency ratio of 0.85 is a candidate for allocation. The efficiency ratio, not the headline return, is the metric that predicts future performance. Start free to run walk-forward tests on your own strategies.
See it in the app
Live dashboard views that match this post. Each tile deep-links to the exact card.
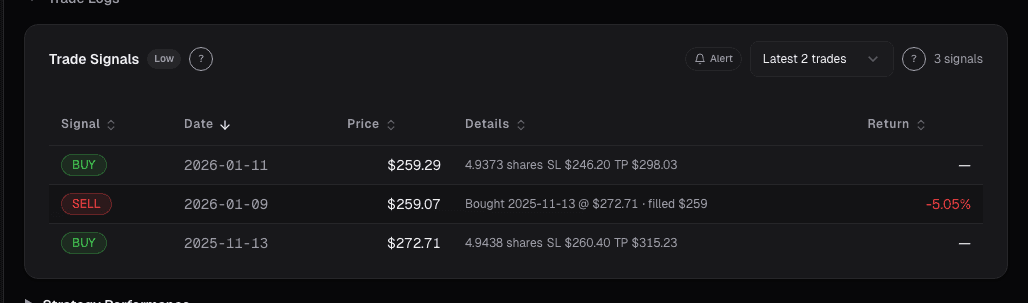
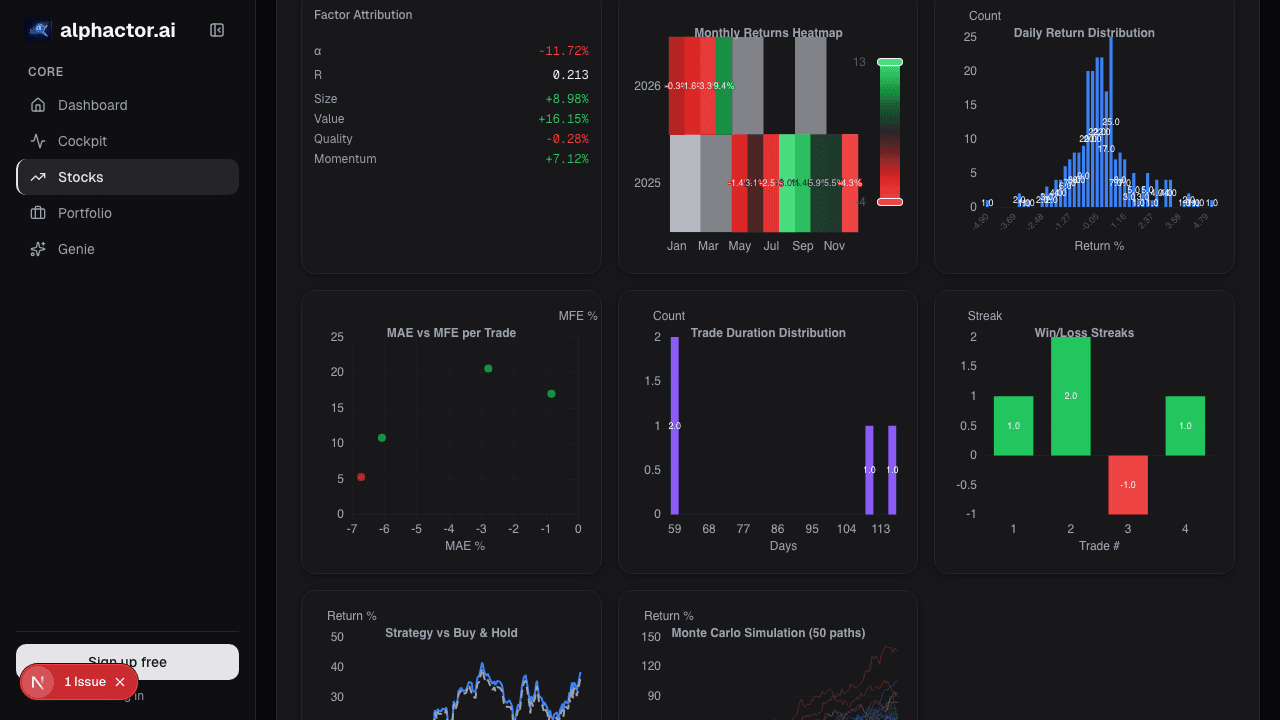
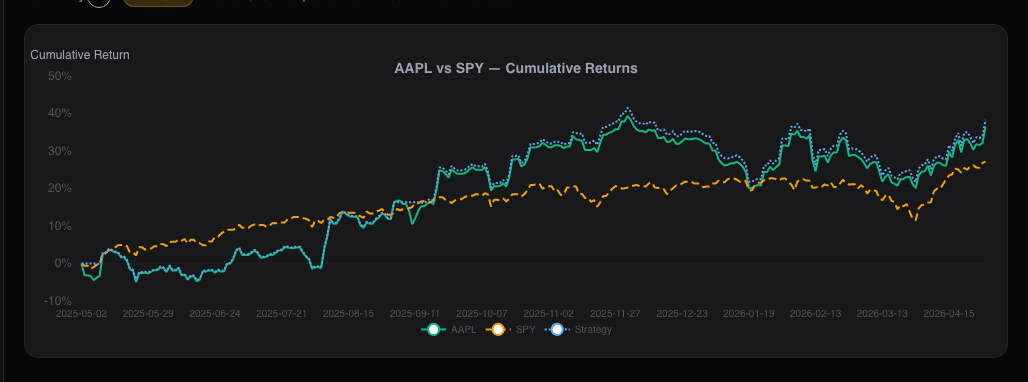
Stocks mentioned
Related reading
Why Most Backtests Lie
How Alphactor's 8-layer credibility pipeline catches overfitting, data snooping, and curve-fitted strategies before they cost you money.
Breakout Strategies
A systematic look at breakout trading across 500 stocks over 10 years, with real numbers on win rates, expectancy, and the filters that separate signal from…
How to Backtest a Trading Strategy (The Right Way)
Learn how to properly backtest trading strategies, avoid common pitfalls like overfitting, and use statistical credibility testing to validate your results.
Regime-Aware Strategy Selection
Markets cycle through trends, ranges, and shocks. Learn how regime detection drives which strategy runs, and why a mixture of experts beats a single static…
Survivorship Bias: The Invisible Flaw in Your Stock Screener
Survivorship bias silently inflates backtest returns and warps stock screener results. Here is how it works and what to do about it.
Ready to try alphactor.ai?
Validate your trading strategies with statistical credibility testing. Start free.
Get Started Free