Part of: Risk Management
Portfolio Optimizer: From Holdings to an Efficient Frontier
Naive mean-variance overweights recent winners. Running MVO, risk parity, and Black-Litterman in parallel shows which allocation choices are robust vs. fragile.
 Marcus Chen7 min read
Marcus Chen7 min readIn 2015 I fed a naive mean-variance optimizer a 10-stock portfolio and 5 years of trailing returns. It told me the Sharpe-maximizing allocation was 62% in a single biotech that had tripled over the sample window and 8% in a bond ETF. I implemented it. The biotech proceeded to drop 55% over the next 18 months as a key drug trial missed endpoints; the optimizer's recommendation had been 100% overfit to a specific sample that didn't persist. I lost roughly 20% of the portfolio. The lesson was uncomfortable, the math was correct given its inputs; the inputs were wrong in a predictable way. Trailing returns are not expected future returns, sample covariance is not forward covariance, and the optimizer was mechanically leveraging the exact assumption that broke. I rebuilt the optimization process after that incident using three methods in parallel and high-level conviction overrides. Much less exciting, much more durable.
This post is about the Portfolio Optimizer card, the three methods it exposes, and the discipline of never accepting a single optimizer output at face value.
TL;DR
- The optimizer is one of the most abused tools in quant finance. Garbage-in, garbage-out at industrial scale.
- Three methods address different problems: mean-variance (MVO), risk parity, Black-Litterman. Use all three.
- Positions where all three methods agree = high conviction. Disagreement = ask why before acting.
- Sample covariance is unstable; use shrinkage estimators. The card does by default.
- Optimizer output is a starting point, not an answer. Apply judgment, size constraints, and common sense.
Three ways to solve "what should I own?"
The optimizer is one of the most abused tools in quant finance. Plug in trailing returns, plug in a covariance matrix, push a button, and the answer is always *wrong* in the same way, it overweights whatever recently outperformed and under-weights everything else, because the estimates are overfit to the sample. Expected-return inputs are the biggest offender; historical average returns are weak estimators of future expected returns and mean-variance optimization (MVO) magnifies every estimation error in the input.
The Optimizer card doesn't hide from this. It offers three methods that each fix part of the problem:
- Mean-variance with shrinkage. Classical MVO with Ledoit-Wolf covariance shrinkage and optional Bayesian shrinkage on expected returns. Still sensitive to return assumptions; less sensitive than naive MVO to covariance estimation error.
- Risk parity. Each position contributes equally to total risk. Return assumptions are removed from the objective, which eliminates the single biggest source of estimation error. Mechanically overweights low-vol assets, which is a feature in most environments but a bug when vol regimes shift.
- Black-Litterman. Blends equilibrium-implied returns (reverse-optimized from market weights) with the user's explicit views. Produces stable allocations that deviate from equilibrium only where the user has explicit conviction.
Using all three and comparing is the discipline.
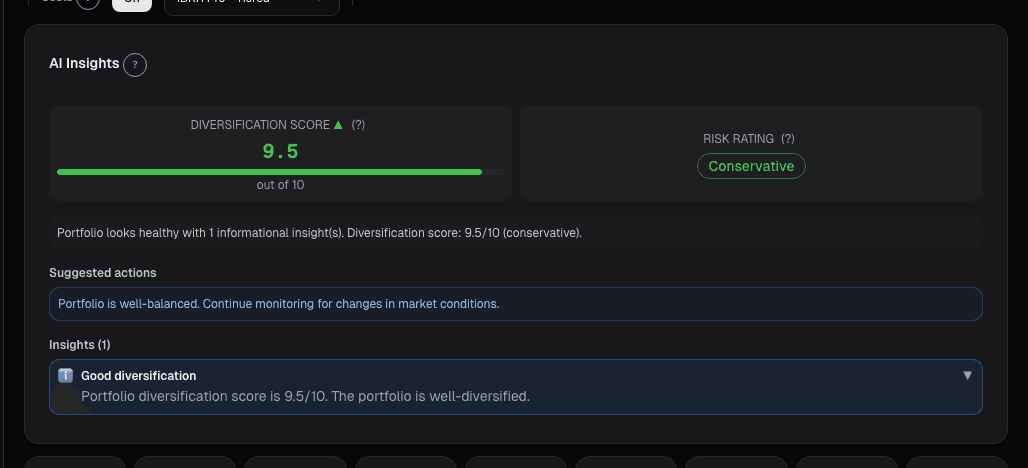
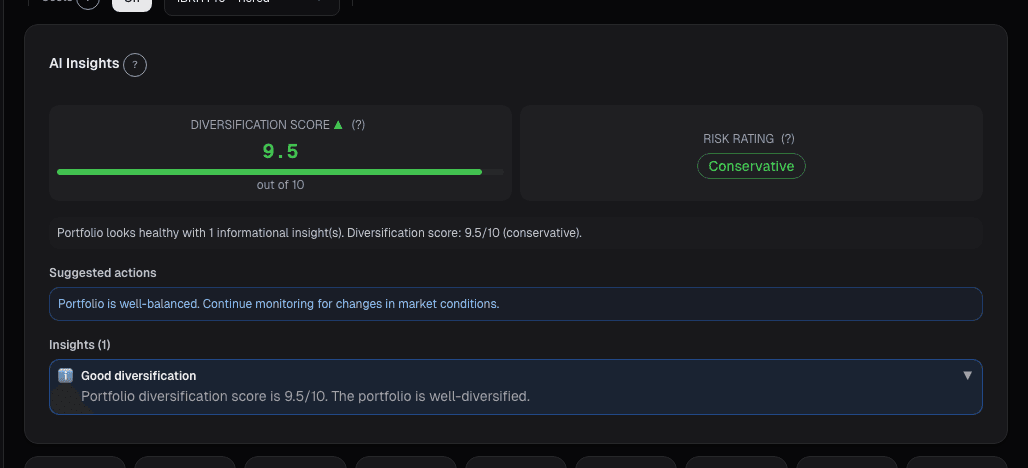
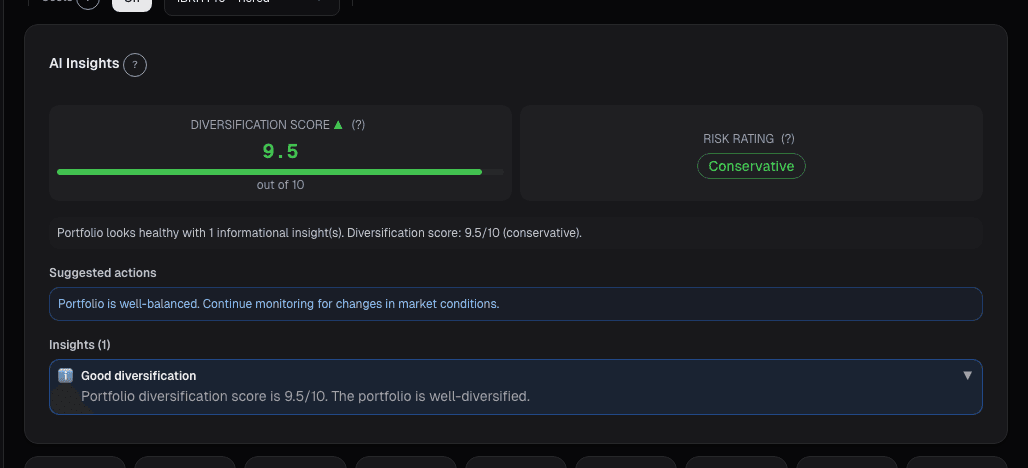
What the Optimizer card shows
The Portfolio Optimizer card takes your current holdings + benchmark universe and computes optimal weights:
- Three objective modes (MVO, risk parity, Black-Litterman) runnable in parallel with a side-by-side comparison view
- Proposed weights: per-position target weight under each method, alongside your current weight
- Expected return, expected volatility, tracking error vs. benchmark: point estimates with Bayesian credible intervals, not single numbers (to avoid the precision illusion)
- Constraints: min/max per position, sector caps, maximum turnover from current weights, no-short default (toggleable)
- Trade list: proposes buy/sell orders in dollar amounts sized to your AUM, routed to the Rebalancing card for execution
- Robustness diagnostics: how much does the proposed weight change if you add random noise to the inputs, shorten the estimation window, or drop the best-performing name from the sample? Highly-sensitive positions are flagged as "unstable"
Using it without fooling yourself
Never accept MVO output at face value. It's always overfit to the input sample. Use it as a directional suggestion, "the math wants to push here", not as a target. The robustness diagnostic on unstable positions tells you which recommendations to distrust most.
Risk parity is more robust but has its own biases. No expected-return inputs means the estimation-error problem goes away. But risk parity mechanically overweights low-vol assets (bonds, defensive equities, low-vol factor tilts) and tends to be leveraged-long-bonds implicitly. In rising-rate regimes this hurts. Read risk parity as one anchor, not the answer.
Compare across all three methods. Positions where MVO, risk parity, and Black-Litterman all agree you should hold a similar weight are high-conviction; positions where only one method suggests a specific weight are the ones where the recommendation is method-dependent. The agreement table at the top of the card summarizes this, the names where all three converge are usually the ones that survive any sanity check.
Constrain aggressively. Unbounded optimization will recommend extreme weights. Hard caps (20% per position, 40% per sector) limit the worst concentration risk without giving up most of the optimization benefit. The card defaults to reasonable caps; adjust for your portfolio's style.
Turnover-limited optimization. Running the optimizer to rebalance-everything every quarter creates transaction costs and tax drag that often eat the proposed improvement. Set a max-turnover constraint (e.g., 15% of portfolio per rebalance) so the optimizer only moves where it's confident enough to justify the cost.
Example: a three-method comparison
Q3 2024 I ran the optimizer on my core book (12 positions). The three methods proposed notably different weights on two names:
| Position | Current | MVO | Risk Parity | Black-Litterman |
|---|---|---|---|---|
| Name A (growth software) | 8% | 18% | 6% | 9% |
| Name B (defensive staple) | 10% | 3% | 15% | 11% |
MVO wanted to double the growth software name because its trailing 12-month Sharpe was strong. Risk parity wanted to cut it because vol was higher than the defensive staple. Black-Litterman, which incorporated my moderate-bullish explicit view on the software name, landed near my current weight. I went with the Black-Litterman suggestion, close to current, reflecting my fundamental view without overdoing the trailing-return bet. Six months later MVO's overweight call would've produced ~2% alpha; risk parity's underweight would've cost ~1%; Black-Litterman split the difference. The lesson was less "which method wins" and more "the disagreement itself told me the positioning was consensus-reasonable, and I shouldn't bet the book on any single method's answer."
What the optimizer can't fix
- Wrong input universe. If the universe excludes an asset you should be considering, no optimization will include it. The universe selection is a prior decision.
- Regime changes. All three methods use historical data; a sudden shift in correlations or vol (COVID, rate regime change) makes recent history misleading for short-term allocation decisions.
- Tax considerations. Tax-loss harvesting, wash-sale rules, lot selection, the optimizer recommends weights; the tax engine needs to interpret them within account structure.
- Liquidity constraints. Recommendations don't account for position-size vs. market-liquidity constraints in small-cap or illiquid names. Overlay these manually.
- Strategic changes. Optimizer is a tactical tool for weights within an existing strategy. Fundamental strategy shifts (long-only to long/short, US-only to global) are separate decisions.
Common mistakes
- Using trailing returns as expected returns. The single biggest error in naive MVO. Use equilibrium or model-based expected returns, or remove return inputs entirely via risk parity.
- Re-optimizing too frequently. Quarterly or semi-annually is usually enough. Monthly re-optimization creates noise-driven turnover.
- Ignoring constraints. Unbounded optimization gives extreme weights. Always constrain.
- Trusting a single method. Use all three; distrust disagreement; act on agreement.
- Treating expected-return point estimates as precision. The credible intervals are often wider than the differences between methods. Act on the structural direction, not the decimals.
Where it fits
The optimizer output flows naturally into the Rebalancing card for execution planning and TCA for understanding the implementation cost of the rebalance. Cross-check optimizer proposals against Factor Analysis, if the proposal changes your factor exposure significantly, ask whether that factor bet is intentional. Confirm with Attribution post-implementation to see whether the optimized allocation actually produced the expected result.
FAQ
What covariance shrinkage estimator does the card use?
Ledoit-Wolf by default, which shrinks toward the constant-correlation target. An alternative (identity target) is available for high-dimensional cases. The estimator choice matters less than using *some* shrinkage; raw sample covariance is unusable at any portfolio size above a dozen positions.
Can I use my own return views in Black-Litterman?
Yes, the card accepts explicit view inputs (absolute: "I think X returns 8%"; relative: "I think X outperforms Y by 3%") with confidence levels. The blended posterior return vector is used in the optimization.
What's the right optimization window?
Covariance estimation: 3–5 years of monthly returns balances responsiveness to regime changes with estimation stability. Shorter windows (1 year) are too unstable; longer (10+ years) absorb old regimes that no longer apply.
Is leverage supported?
No-short is the default. Long-short and leveraged optimization are available but require explicit opt-in and reasonable gross-exposure constraints.
How do I handle illiquid positions?
Constrain them to their current weight (lower/upper bound = current). The optimizer then works around them instead of proposing unreachable trades.
Related reading
Open the Portfolio Optimizer → /app/portfolio
See it in the app
Live dashboard views that match this post. Each tile deep-links to the exact card.
Related reading
Alt-Data Sentiment at the Portfolio Level
Per-ticker alt-data breaks down past 10 positions. A roll-up of WSB, news, MSPR, and options lets a 90-second scan replace 100 minutes of manual checking.
Portfolio Attribution: Where Your Returns Actually Come From
Beating the benchmark by 400bps feels good until attribution tells you it was all allocation luck on one sector call. Selection vs. allocation vs.
Portfolio Audit Trail: Every Decision
Regulated managers need an audit trail. The Audit Trail card on alphactor.ai records every trade, rebalance, alert, and note into one timestamped log you…
Portfolio Credibility
Conviction is self-reported; credibility is externally anchored. The two diverge exactly where mistakes live, an 8% position in a name you love with a…
Risk Parity: Allocating by Risk, Not by Dollars
How risk parity portfolios work, why they differ from traditional allocation, and how to apply the concept without a PhD in finance.
Ready to try alphactor.ai?
Validate your trading strategies with statistical credibility testing. Start free.
Get Started Free